Создание шаблона происходит на верхней панели основного меню Дизайнера во вкладке «Разработка» — раздел «Запись» — «Извлечь по шаблону».
Извлечь по шаблону
При нажатии на кнопку «Извлечь по шаблону» открывается обработка «Генератор шаблонов» (Шаблонизатор).
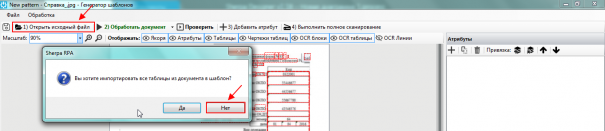
При создании нового шаблона происходит автоматическое распознавание документа. Так как мы создаем шаблон документа, с которым ранее не работали, нам необходимо создать новые якоря и привязки к тем значениям, которые будут обрабатываться роботом именно в данном типе документа. Поэтому на сообщение во всплывающем окне «Вы хотите импортировать все таблицы из документа в шаблон» отвечаем «Нет».
Распознавание текста
Распознавание текста в Шаблонизаторе производится с помощью встроенных и внешних модулей распознавания:
В платформе Sherpa интегрированы несколько OCR -модулей. Два из них – офлайн (поставляются вместе с роботом), и будут работать без подключения к интернету. Это Tesseract OCR и Microsoft OCR.
Yandex Vision и ABBYY OCR – онлайн-модули, т.е. используют функции соответствующих облачных модулей.
ABBYY Fine Reader – это коммерческий офлайн-модуль, использование которого требует отдельной лицензии.
Платформа позволяет настроить работу сценария с распознаванием изображений и переключаться между этими движками в любой момент времени. Для этого необходимо выбрать желаемый движок из списка.
В случае, если распознаваемый документ высокого качества, с высоким расширением, то достаточно использовать бесплатные OCR-модули.
При обработке документов низкого качества лучше использовать платные решения.
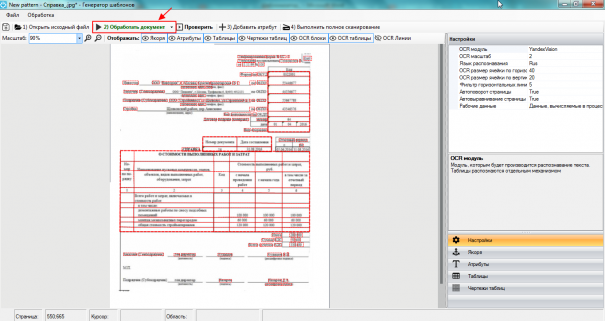
После того, как основные параметры настроек заданы, документ необходимо обработать. Действие запускается нажатием кнопки «Обработать документ».
Обработанный документ выглядит так, как показано на скриншоте выше.
Сохранить шаблон
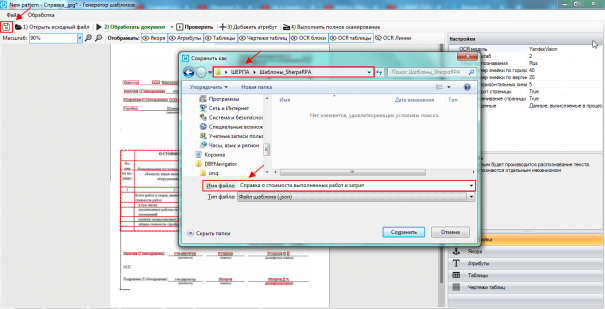
Для дальнейшей работы с шаблоном его нужно сохранить, нажав на иконку  в левом верхнем углу основной панели действий. Далее указываем путь для сохранения шаблона и имя файла. Имя файла указываем исходя из вида документа, например, «Справка о стоимости выполненных работ и затрат».
в левом верхнем углу основной панели действий. Далее указываем путь для сохранения шаблона и имя файла. Имя файла указываем исходя из вида документа, например, «Справка о стоимости выполненных работ и затрат».