
Работа с многостраничными документами
При создании шаблонов для многостраничных документов необходимо определить уникальные якоря, поиск по которым будет осуществляться только в определенном типе документа. Например, в документе УПД может встречаться слово счет-фактура, соответственно, не нужно использовать это слово в качестве якоря ни для УПД, ни для Счет-фактуры.
При необходимости работы с многостраничным документом, бывает, что один документ находится на нескольких страницах.
Для каждого типа документов необходимо создавать отдельный шаблон (например, 1 — Торг12, 2 – Счет-фактура, 3 – УПД), и указать все типы документов в значениях переменной. При этом тип переменной выбрать List (список).
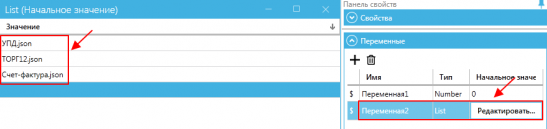
Далее указываем путь к файлу шаблона:
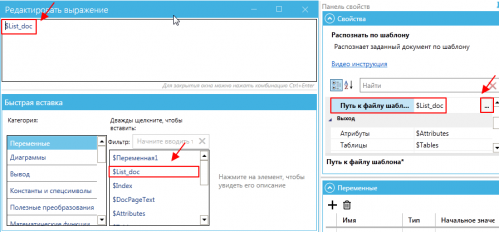
Указываем Номер страницы – 1, для того, чтобы распознавание начиналось с первой страницы. Также указываем путь к файлу.
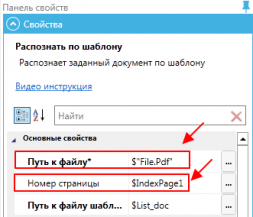
Завершение работы робота при возникновении ошибки
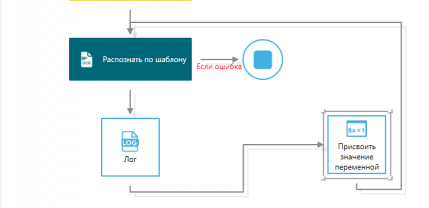
По окончании работы по создания шаблона, необходимо прописать дальнейший сценарий его распознавания и вывода результатов.
Если робот не смог произвести распознавание документа, то сценарий может быть остановлен. Для этого в Sherpa Designer добавляем блок «Конец». Также можно добавить блок «Лог» для записи ошибки в лог.

Ошибка распознавания может возникать в случаях, когда ни один из шаблонов не подошел или, когда не осталось документов для распознавания.
В случае, если в PDF файле находятся несколько документов, и один из типов документов неизвестен роботу (т.е. на этот тип документа нет шаблона), робот будет пропускать этот документ и будет распознавать лишь те документы, для которых есть шаблоны.
Поиск второго и последующих документов в многостраничном файле
После того, как в многостраничном документе был распознан один из шаблонов, необходимо внести изменения в прописанный индекс (прибавить), чтобы дальнейшее распознавание началось не со следующей страницы, а после найденного документа.
Так как в атрибутах существует параметр CountPage, который соответствует количеству страниц, участвующих в распознавании шаблоном, то для продолжения процесса распознавания нужно добавить этот параметр к индексу.
Таким образом, если в многостраничном документе был распознан первый документ, занимающий несколько страниц, при добавлении параметра CountPage дальнейшее распознавание начнется со страницы, следующей после распознанного документа.
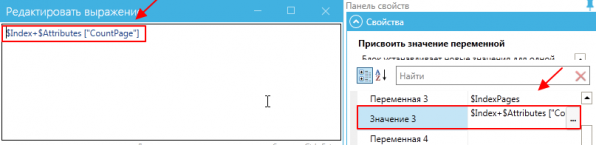
После этого настраиваем сценарий на повторное распознавание документа.
Last updated